
New breakthrough in TeamFree noise reduction algorithm
Online models such as online meetings, online education, and live broadcasts have changed the traditional interaction models in offices, education and other industries, and have become an emerging necessity. Applications that were originally in niche fields are penetrating into wider fields. TO C application scenarios have gradually become the mainstream trend in the industry. Many traditional conference equipment brands have launched a variety of call noise reduction products, such as conference speakers, Bluetooth speakers with call noise reduction, etc. Judging from the current market situation, products are still concentrated in high-end and professional fields, and consumer-level applications belonging to the public are still a blue ocean market with great development prospects.
It was against the background that the industry was improving that the author received the research and development task of developing an all-in-one conference machine. The reference at the beginning of the design of the all-in-one conference machine was notebooks and tablets. This type of tablet device integrates peripherals such as cameras, microphones, speakers, screens, etc., and integrates various conference equipment into one. It seems to fully meet the requirements of an all-in-one conference machine. However, the author has made a lot of traditional conference equipment, and the experience of using traditional conference equipment to hold meetings completely surpasses that of laptops or tablets. Taking a notebook as an example, the differences are as follows:
- Traditional conferences are connected to a large screen, with a wide field of view, dual-stream high-definition, and high video quality. Laptop cameras are far behind, with low video quality, narrow field of view, and no ability to connect to external video sources.
- Traditional conferences are mainly room conferences. The power of the speakers is high. The sound can reach 90 decibels in the near field and 80 decibels in the far field. You can hear clearly regardless of the distance. Laptop speakers are mainly used for music playback, with small sound cavity and poor bass performance.
- Traditional conferences use microphones, and the sound signal-to-noise ratio is very high. When multiple people participate in the conference, the accent and emotion of each speaker can be accurately identified. The built-in microphone of the notebook mainly picks up sound in the near field, and the pickup distance is relatively close and the noise is relatively large.
- Traditional conferences support multi-channel voice, and local sounds and multi-party voices can be mixed. The notebook can only mix multi-party voices and cannot mix local video sounds.
Among the above items, compared with the professional-level meeting effect, the most tiring thing when conducting online meetings with this type of tablet device is the inextricable noise, the frequent harsh whistling, and the harsh voice. , after a long meeting, the experience is really dizzying. Therefore, in order for the all-in-one conference machine to achieve professional conference results, the most important requirement is professional-grade sound effects. Therefore, the first challenge of research and development comes. The voice in video conferencing must be clear and comfortable. How to ensure clear and comfortable voice?
The author has been engaged in the research and development of video conferencing terminals for many years. It stands to reason that the answer is very clear. As long as the sound played back is clean human voice, the effect will be very good. In terms of technical implementation, it means a good microphone, a good speaker, a good sound chamber, a stable base with good vibration damping effect, an amplifier with a wider power bandwidth, and other hardware, as well as the well-known ANS, AEC, The general algorithms of AGC and EQ can be combined together.
But the author quickly stumbled upon a problem, which was the noise reduction process. The purpose of traditional noise reduction processing is to improve the signal-to-noise ratio. When the author played the sound with the improved signal-to-noise ratio on the device at 90 to 100 decibels, the result was that it was mechanical, metallic, and the sudden sound was harsh. The conclusion was that it was unacceptable. The traditional video conferencing terminal has a very good experience when playing low-power speakers or headphones at close range. What’s the difference?
- The microphone of traditional conference terminals has good directivity, relatively close pickup distance, clean sound, and high signal-to-noise ratio. The all-in-one conference machine needs to pick up sound from a long distance, and the noise in the space has spatial uniformity. Human voices attenuate exponentially as the distance increases, and the signal-to-noise ratio drops rapidly. Similarly, in order to ensure long-distance sound pickup, when no one speaks, the noise will be absorbed completely and the sound will not be clean. The traditional noise reduction algorithm essentially refers to the background noise for noise reduction. The greater the background noise, the greater the voice noise reduction.
- When picking up sound in the far field, when the speaker plays sound at a power of 90 to 100 decibels, the sound played locally will exceed the voice reaching the microphone by 30 to 40 decibels. This limits the gain to the microphone signal because the upper limit of the quantization range is limited by the sound being played, which results in increased quantization noise.
- When noise is inevitably collected, it is difficult to find a unified, clear and quantifiable description, which brings great limitations to speech noise reduction. Generally speaking, for noise with obvious statistical characteristics, current speech noise reduction algorithms have theoretically feasible and practical results. The main method is to use the statistical characteristics of noise to estimate the noise, and then subtract the noise component from the noisy speech to obtain pure speech. The currently more successful algorithm is noise estimation based on maximum likelihood ratio, but this algorithm assumes that the noise power spectral density is Gaussian distribution, which obviously has great limitations. However, sudden, variable-frequency noise cannot be accurately estimated and eliminated using such algorithms.
- When reproducing the spatial sound field, the bass is required to be full and soft, the mid-bass is rich and powerful, the mid-range and treble are bright and clear, and the treble is slender and clean. At the same time, the human auditory system can easily separate the sound source from the noisy environment in the spatial sound field. This phenomenon shows that it is not enough for the sound to have a high signal-to-noise ratio. Even if the intelligibility is high, if the sound is not balanced enough, it will sound very uncomfortable; and a low signal-to-noise ratio does not necessarily lead to poor sound quality. experience.
After analyzing these differences, the author realized that traditional noise reduction algorithms may not be able to solve new problems. Traditional algorithms estimate noise through statistical methods and can play a better role in reducing steady-state noise. However, in Under noise types such as unsteady noise and transient noise, traditional noise reduction algorithms often cannot achieve better results. In particular, traditional noise reduction algorithms may not be able to guarantee the sense of space of the sound, and this sense of space cannot be achieved in all-in-one conference machines. crucial to the experience.
The author has no choice but to turn his attention to the AI technology that has become popular in recent years. After data collection, it was found that in the field of audio processing such as noise reduction, there have been many noise reduction algorithms based on Artificail Intelligence (AI) or artificial neural network models. These AI algorithms have greatly improved their noise reduction capabilities compared to traditional algorithms. Ignoring the limitations of device computing power, storage volume, etc., let’s try it first.
Let’s first take a look at how the AI noise reduction algorithm is implemented step by step. First of all, we must know that the construction of AI models generally uses a large amount of data training to allow the model to learn the information hidden in the data. This is the so-called machine learning. In the field of noise reduction, the input of the model is a noisy speech signal, and the output of the model is a pure speech signal. Through a large number of such pairs of noisy and pure speech data, the AI model is trained to make it capable of noise reduction. Ability. Secondly, you need to know the structure of common AI noise reduction models and the training methods of AI noise reduction models. AI models often use artificial neural networks to simulate the memory and signal processing capabilities of human brain nerves. Common types of artificial neural networks include Deep Neural Network (DNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), etc.
Okay, the study is over, two conclusions:
- There are many AI noise reduction models, and there are many open source ones. If you are not too familiar with neural network optimization, just pick a model with good real-time performance. First of all, I believe that the level of these models is relatively high, otherwise they would not be famous in the industry.
- Big data training is essential. To be effective, you have to collect your own data.
The author’s approach is very simple. I use equipment to collect various noises in the actual environment, collect standard human voices in a silent room, and then put them together with open source samples for training. The advantage of such training is that it not only ensures the generalization ability of the model, but also improves the model’s processing effect on the actual sound collected by the device. The characteristic of the neural network is that you have to give it whatever data you want, so a silent room is just a relatively quiet room that can isolate the noise from outside, and it is almost the same size as a real room. We are the type of anechoic chamber shown in Figure 1, not the type of anechoic chamber shown in Figure 2.

Silent warehouse

anechoic chamber
Once the data is available and the training is completed, update the trained neural network weights and biases into the model to see how effective the AI noise reduction algorithm is.
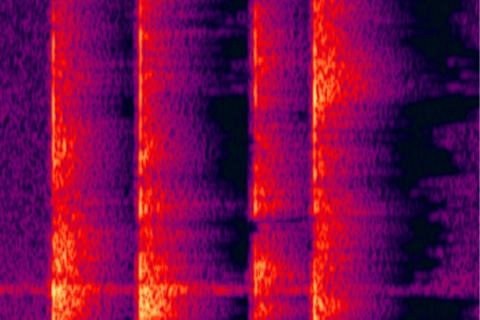
Spectrum before noise reduction
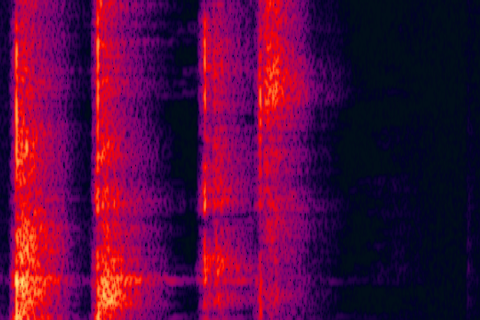
Spectrum after noise reduction
There are three main advantages of using neural network noise reduction:
- There is no strong correlation between the noise reduction effect and the size of the background noise, and the damage to the voice will not be greater when the noise is reduced.
- Specific noise can be removed even if it has no obvious statistical characteristics, such as the noise component enclosed by the black circle in the picture above.
- Complete pure noise removal.
After actual combat, the author realized step by step how to solve the problem of deploying noise reduction algorithms in real-time audio interaction scenarios and achieved satisfactory results. For more experience, please try TeamFree all-in-one conference machine.